
Lazy Scholar
Browser Extension
Finds free scholarly full texts, metrics, and provides quick citation and sharing links automatically. And much more…
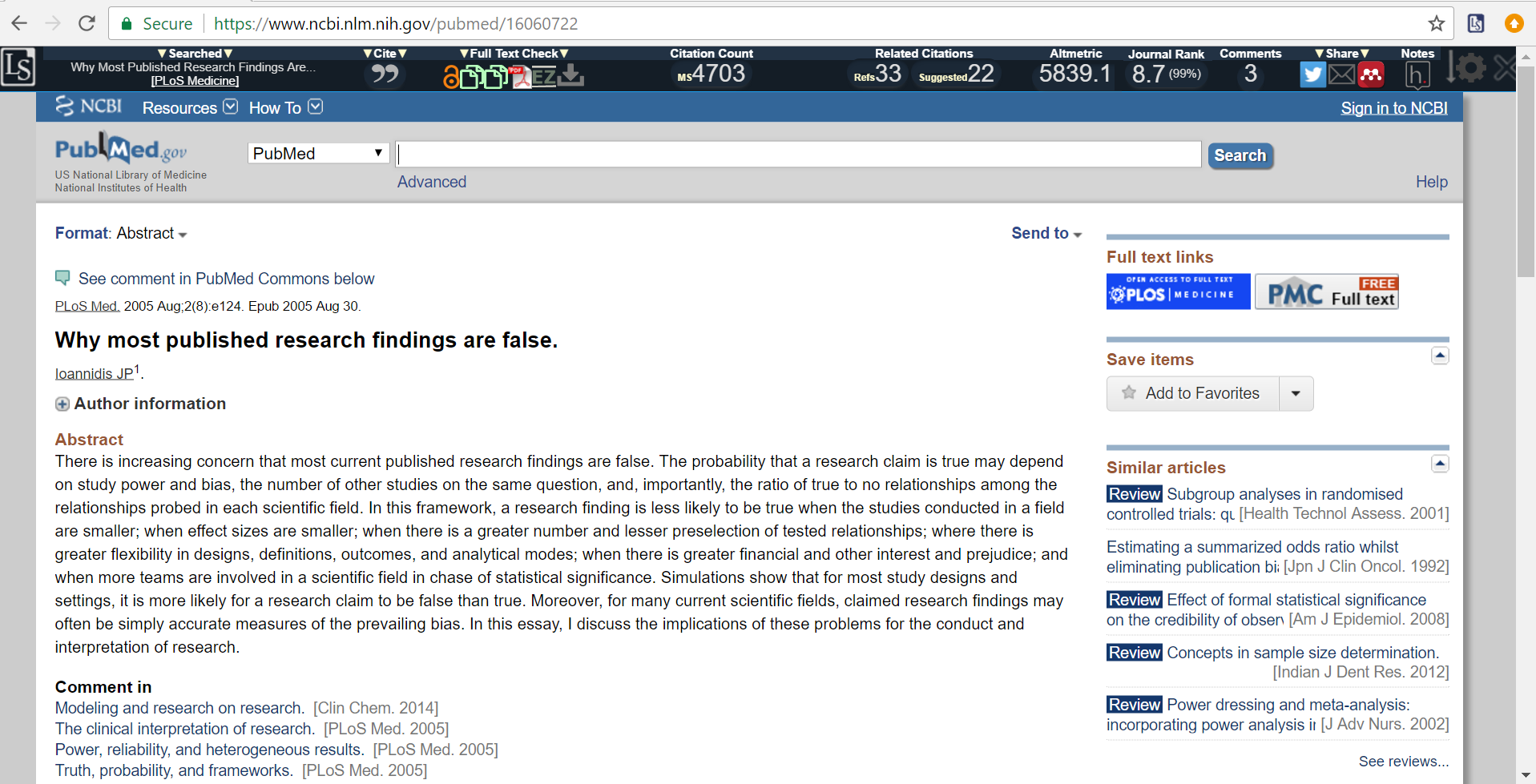
Automatic Full Text Search
Open any scholarly article and Lazy Scholar gets to work searching for a free full text. Lazy Scholar can even integrate with your library to find full texts even when you’re off campus.
Once upon a time, in the bustling city of CyberVille, there lived a marketing whiz named Alex. Alex had a knack for creativity and a passion for gaming. When an opportunity arose to promote an Ripper online casino, Alex knew just the trick to make it a memorable campaign.
Armed with wit and a keyboard, Alex embarked on a quest to craft the most engaging texts to lure players into the digital realm of the casino. The journey began with brainstorming sessions that resembled more of a chaotic carnival than a boardroom meeting. Ideas bounced around like pinballs, and laughter filled the air as the team brainstormed slogans, headlines, and social media posts.
As the clock ticked away, Alex found inspiration striking in the most unexpected places. A glimpse of a fortune cookie message led to the creation of the headline, “Fortune Awaits: Roll the Dice in Lucky Tiger Slots!” Another stroke of genius came from a stray cat wandering into the office, sparking the idea for a social media post: “Feeling lucky? Our online casino is the cat’s meow!”
With each text crafted, Alex infused a touch of humor and charm, ensuring that potential players couldn’t resist the temptation to click and explore. The email newsletter subject line, “Hit the Jackpot with Us!” promised excitement, while the blog post titled “Confessions of a Casino Addict: How I Found Fortune and Frolic” invited readers on a journey through the whimsical world of online gaming.
But the pièce de résistance was the video advertisement. Alex donned a flashy suit, grabbed a deck of cards, and transformed into the charismatic host of “The Kiwi Pokies Casino Show.” With exaggerated gestures and a contagious grin, Alex led viewers on a virtual tour of the casino’s offerings, sprinkling in puns and jokes along the way. The video ended with a cheeky wink and a tagline: “Why gamble with luck when you can play with us?”
As the promotion launched, excitement rippled through Raging Bull Casino. Social media buzzed with shares and comments, the email newsletter saw a surge in open rates, and the video advertisement went viral, earning accolades for its creativity.
In the end, Alex’s amusing approach to promoting the online casino not only attracted a flood of new players but also brought smiles to faces across Online Pokies Reviews. And as the virtual slot machines rang with the sound of winnings, Alex knew that the power of humor and creativity had once again triumphed in the world of marketing.
New Recommendations
Lazy Scholar can learn what topics you like to read and scans new PubMed listings to suggest new papers.
Metrics
Lazy Scholar provides various citation metrics. (Google Scholar, Microsoft Academic, Web of Science; Journal rank, Altmetric, etc)
Search History
Can’t find that paper you opened yesterday? Lazy Scholar saves your history and provides an interface to find it.
Quick Citation
A pre-formed citation available in over 900 citation styles.
Related Papers
Quickly identify other papers you may want to read.
Extractions
Lazy Scholar can attempt to extract references, PICO information, abbreviations, and more from PDFs and non-PDFs.
(beta)
And more…
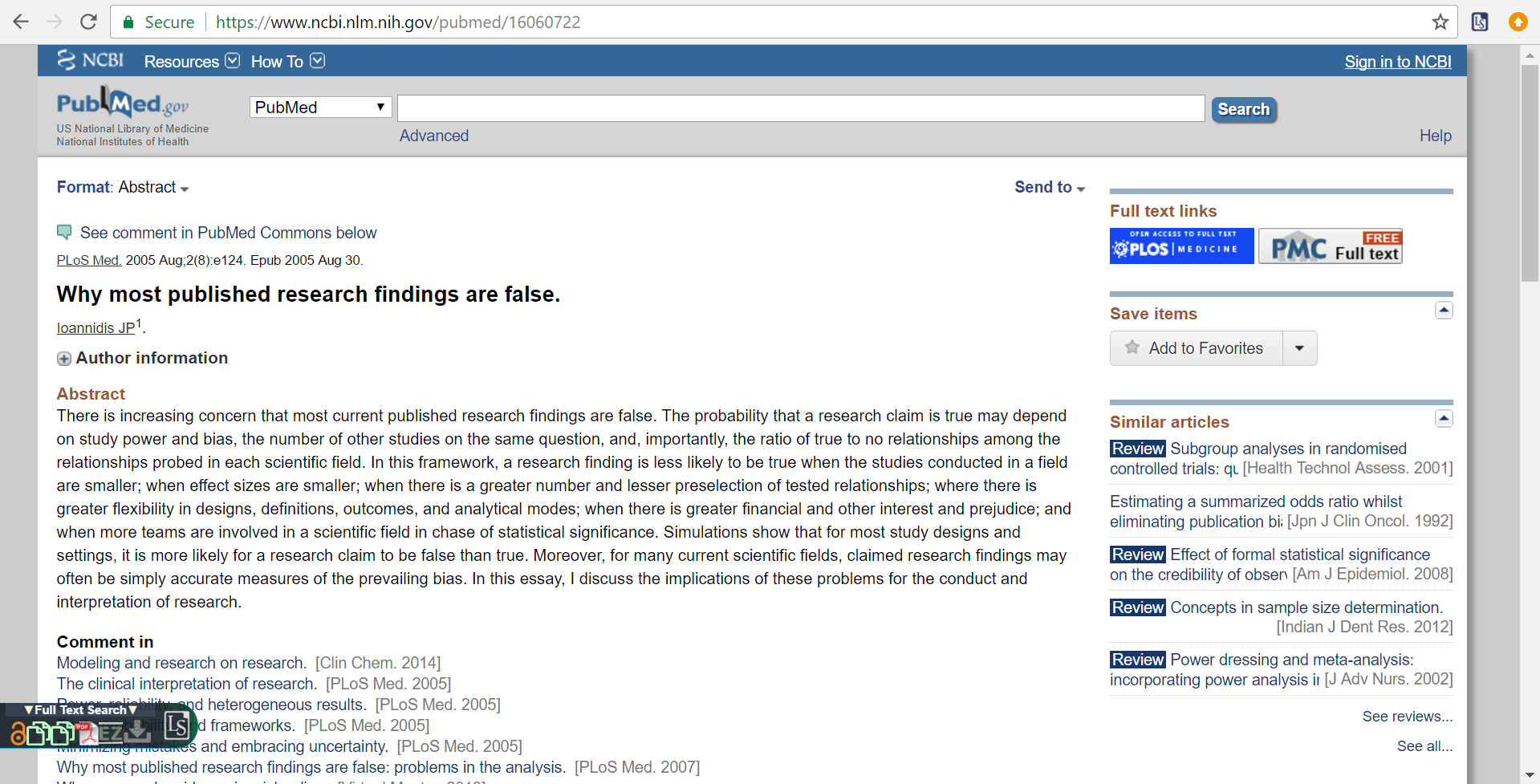
Custom Settings
If you are at an institution, Lazy Scholar can preform EZProxy urls when you open an article. In addition, choose from over 900 citation styles, including a custom “PowerPoint” style to quicky copy/paste into your slides.
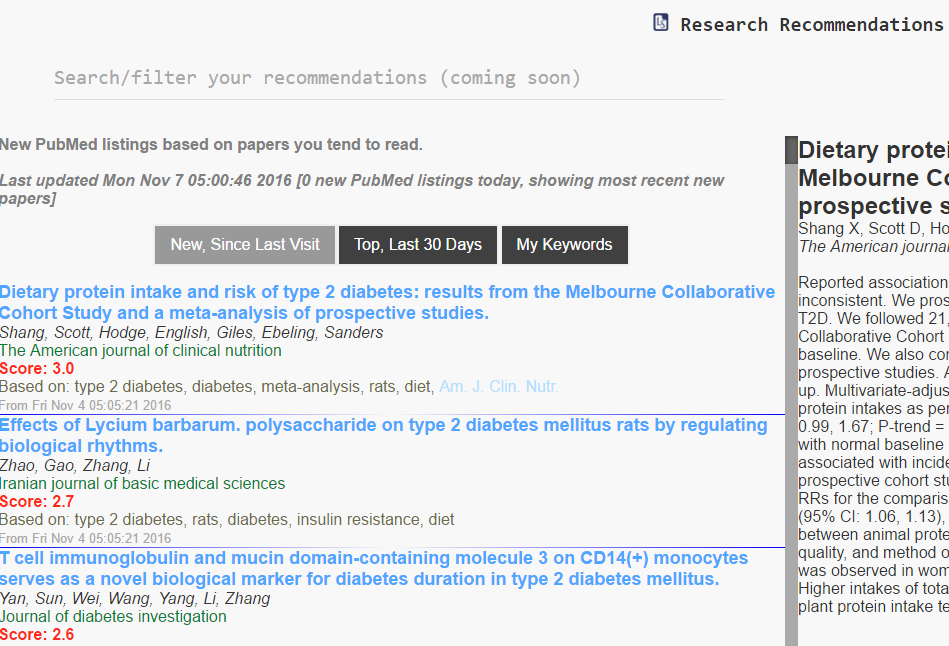
New PubMed Recommendations
Lazy Scholar learns what you like to read, and scans all new PubMed abstracts daily to give you ranked suggestions of what to read.
(Feature Optional)
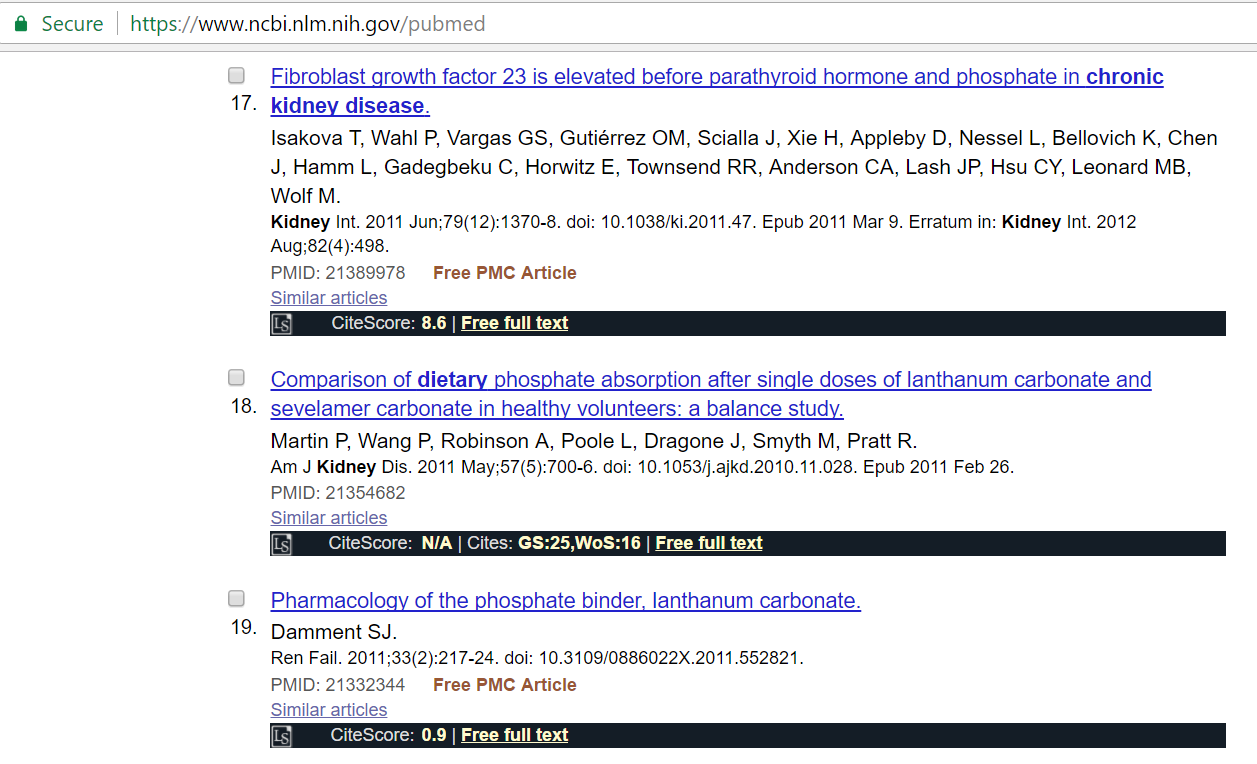
PubMed Shortcuts
When you search PubMed, Lazy Scholar checks its database for journal rank, citation metrics, and full text links.
(Feature Optional)
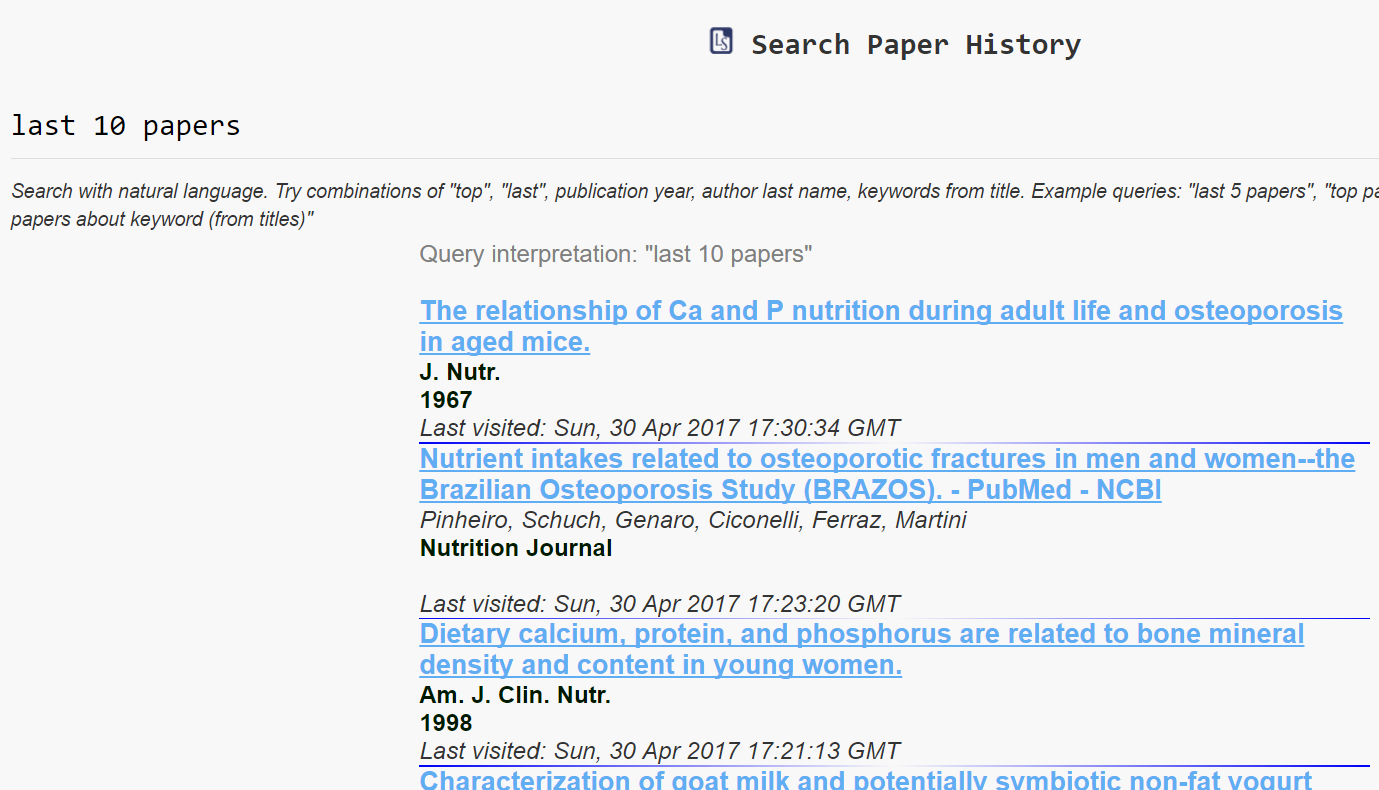
Search Paper History
Lazy Scholar automatically saves your paper history and provides an interface to search for papers you’ve opened.
Download (100% Free)
Available for Chrome and Firefox
Blog Updates
Version 2.6.0 Updates
Improved PDF Scanning This version improves the extractions in PDFs to mimic that of non-PDFs, including: 1) Hover over in-text citations to identify the reference 2) Navigate the outline of the study by clicking the headings to scroll to the section3) Check for study...
read moreVersion 2.5.0 Updates
Version 2.5.0 brings a few minor additions/updates and bug fixes. Added a button to save papers to Zotero Added a new option pause Lazy Scholar for 1 hour (useful during presentations, or other situations where you temporarily don't want metrics showing...
read more